Multimodal Benchmarking
We benchmark prominent SOTA music understanding models on our dataset showcase their performance on a set of canonical and novel metrics.
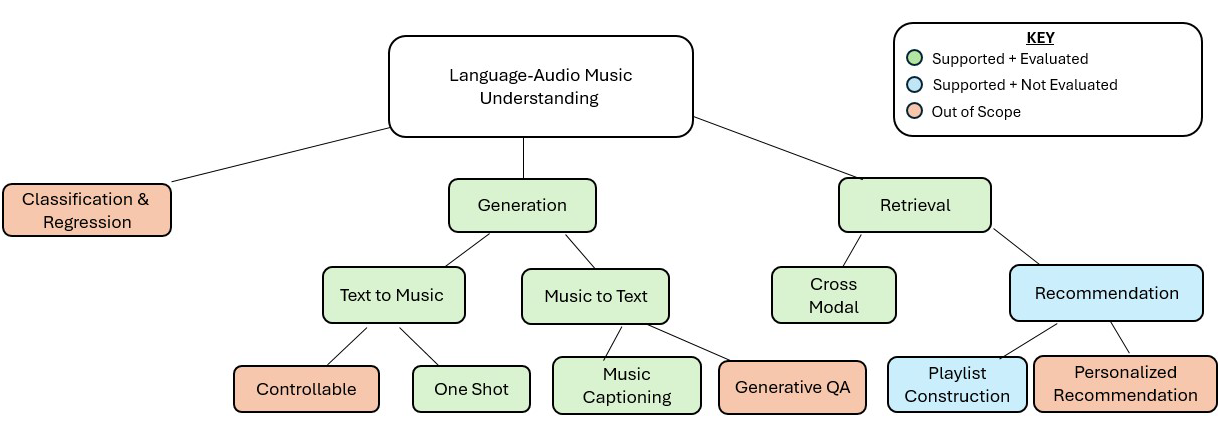
Taxonomy of Multimodal Music Understanding Tasks
Sensitivity Metrics
Given a text-audio pair
where