MusicSem: A Semantically Rich Language-Audio Dataset of Organic Musical Discourse
Abstract
Music understanding underpins a wide range of downstream tasks in music information retrieval, generation, and recommendation. While recent advances in multimodal learning have enabled the alignment of textual and audio modalities, progress remains limited by the lack of datasets that reflect the rich, human-centered semantics through which listeners experience music. In this work, we formalize the concept of musical semantics—encompassing emotion, context, and personal meaning—and propose a taxonomy that distinguishes between five types of music captions. We identify critical gaps in existing datasets, especially those relying on large language model-generated text, and argue for the need to capture more authentic, nuanced musical discourse. To address this, we present a novel dataset of over 40K human-annotated language-audio pairs derived from organic online music discussions. Our dataset emphasizes subjective semantics, including emotional resonance, contextual use, and co-listening patterns. We further validate its utility through a comprehensive benchmarking of state-of-the-art generative and retrieval models, highlighting the importance of semantic sensitivity in advancing multimodal music understanding.
Semantic content in musical descriptions

Visualization of Extraction and Verification Pipeline for Dataset Construction
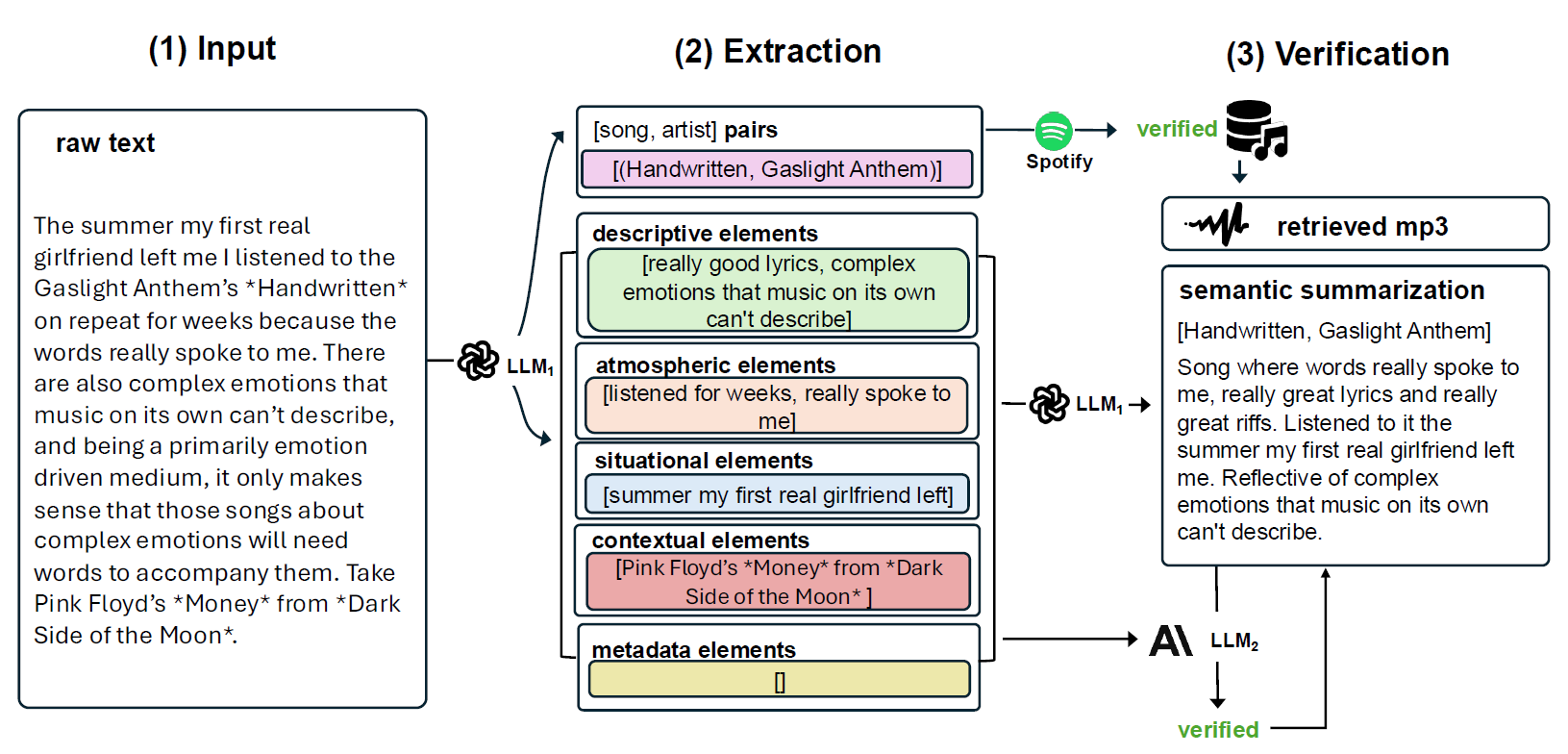
Case Study of Personalization in Reddit Dataset

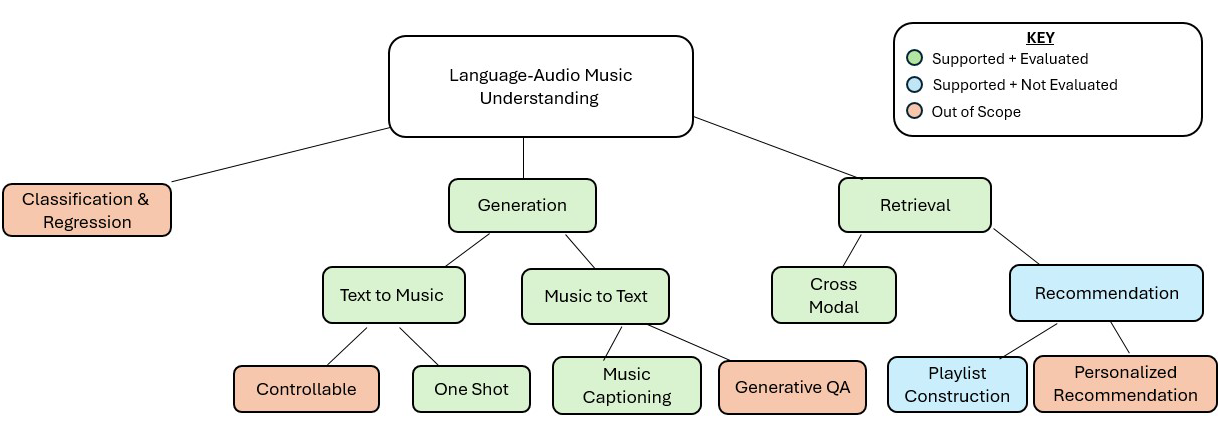
Taxonomy of Multimodal Music Understanding Tasks