Dataset
Data Collection Pipeline
We formalize and design a data pipeline for extracting meaningful semantic captions associated with music audio samples.
Dataset Curation
We design an academic scale dataset that can be used for training or finetuning multi-modal music representation learning models.
Framework
The guiding principles of our dataset include:
- extracting rich semantic information
- limiting the possibility hallucination
- formatting the final music captions to contain a format that is compatible with state-of-the-art (SOTA) generative and retrieval based models.
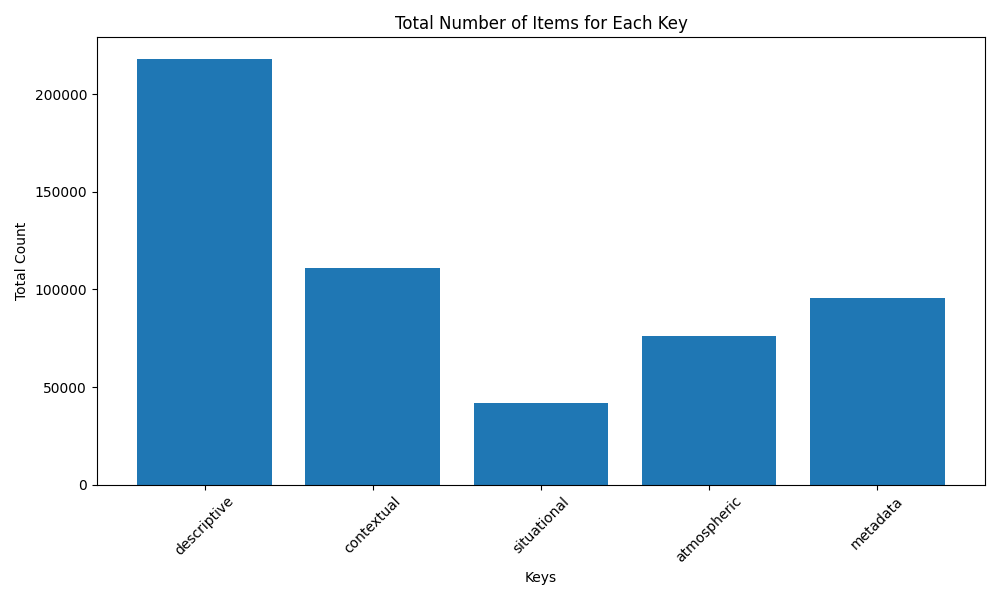
1: 2: posts = Load_Entire_Thread( 3: filtered = Length_and_Mod_Filter(posts) 4: sa_pairs, caption_extracts = 5: descriptive, atmospheric, situational, contextual, metadata = caption_extracts 6: song_ids = Spotify_Metadata(sa_pairs) 7: sa_pairs = Hallucination_Check1(sa_pairs,fltrd) 8: mp3s = Spotify_Audio(song_ids) 9: final_summaries = Summarize(sa_pairs,caption_extracts, mp3s) 10: filtered_captions = Hallucination_Check2(caption_extracts, final_captions, |
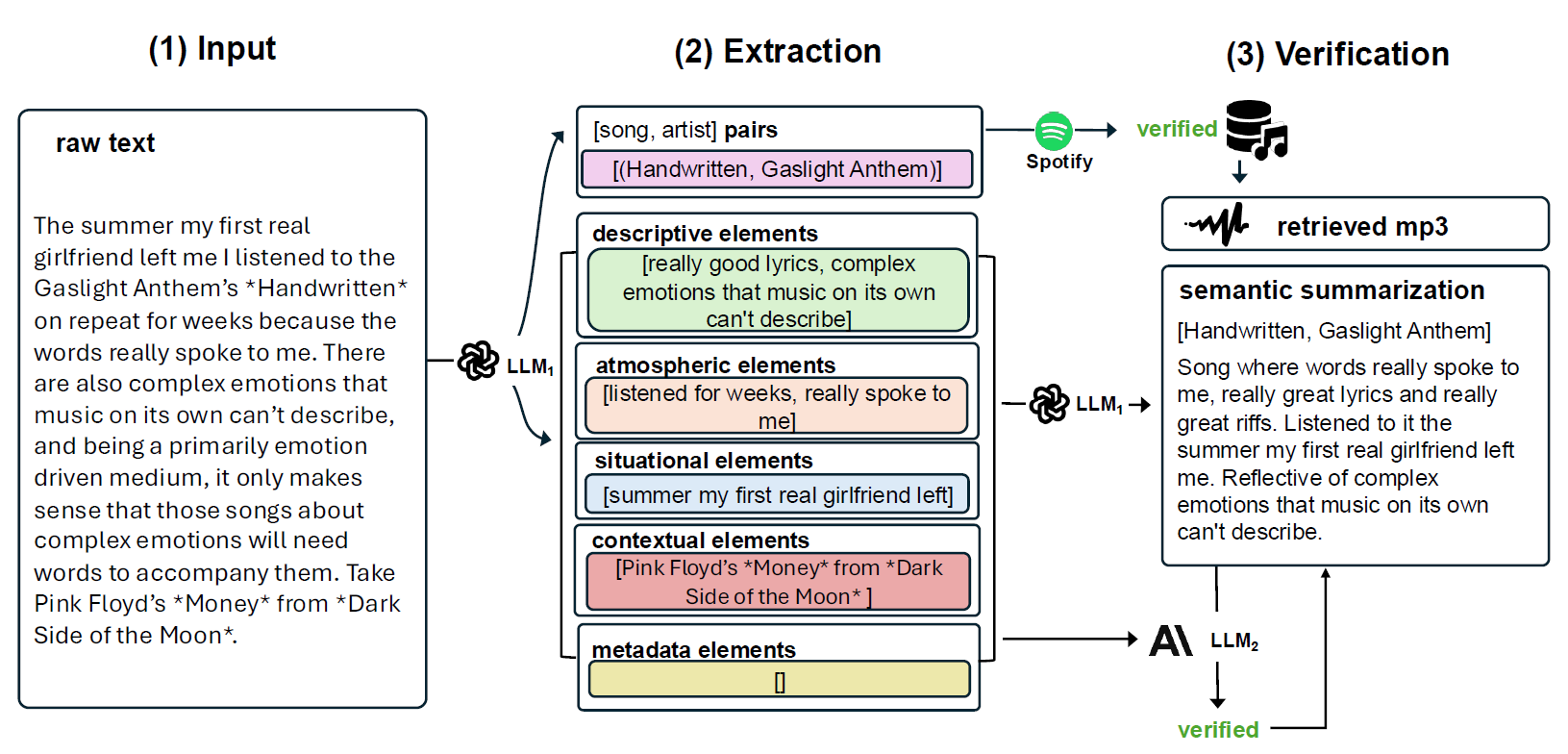
Preview
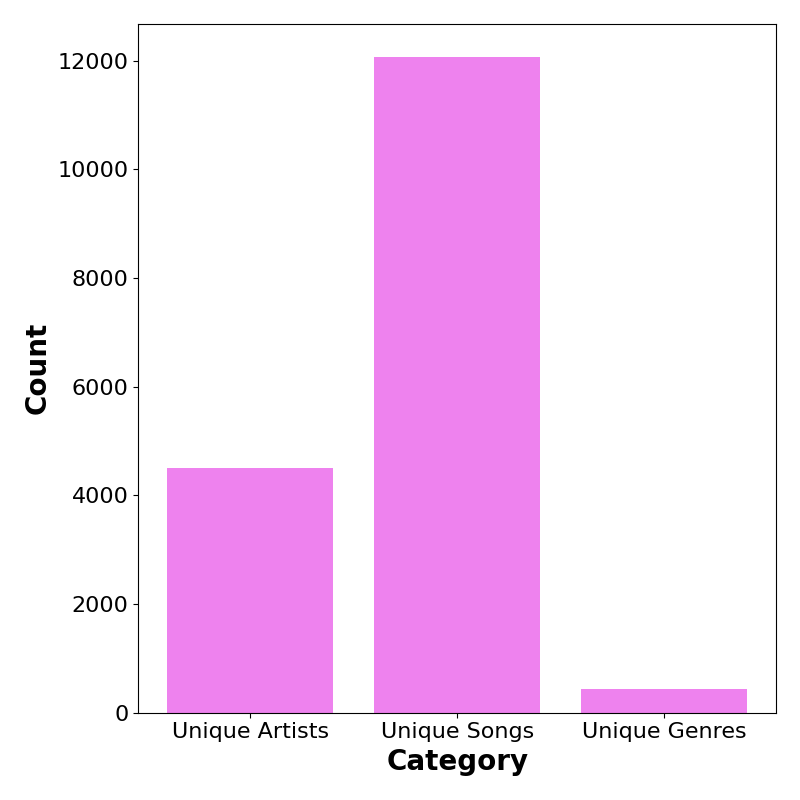
Properties of the Dataset
| Total Size | # Unique Songs | # Unique Artists | # Posts per Song | #Songs per Post | # Genres per Song |
|---|---|---|---|---|---|
| 42,426 | 12,073 | 4.496 | 3.51 | 11.65 | 2.61 |
Number of Unique Entries
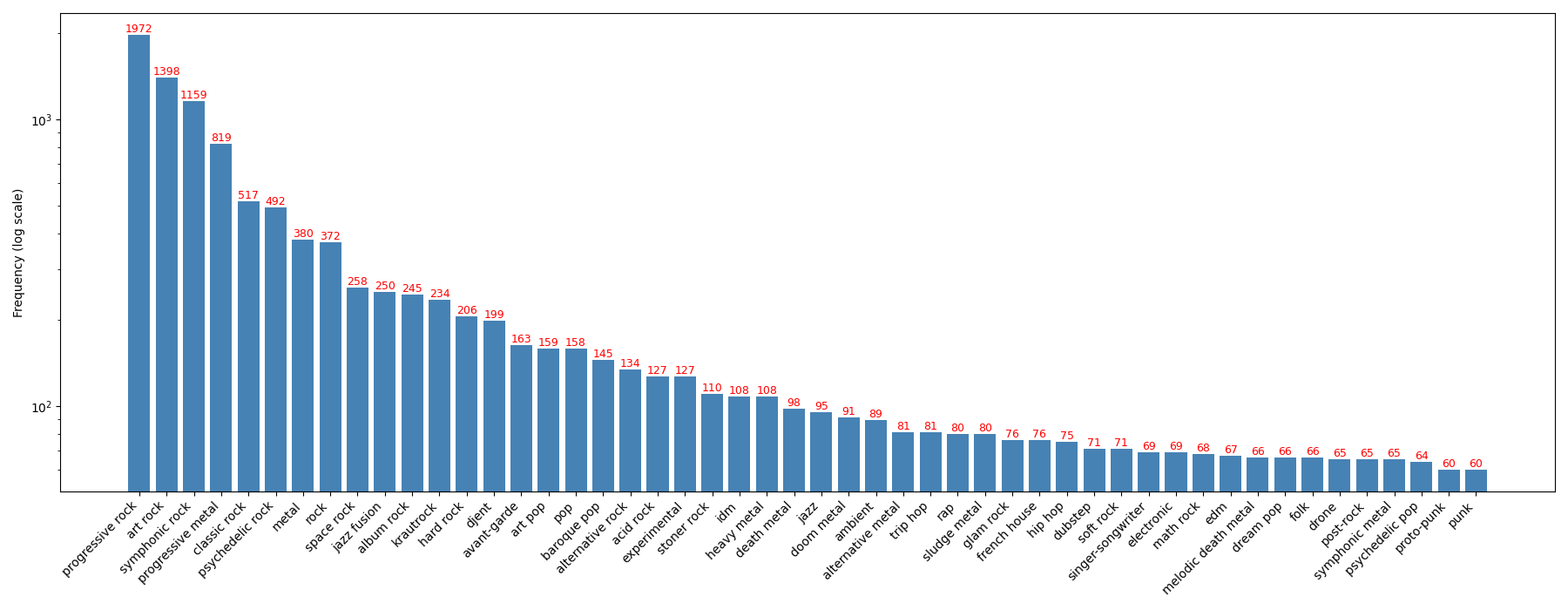
Genres Most Represented in Dataset
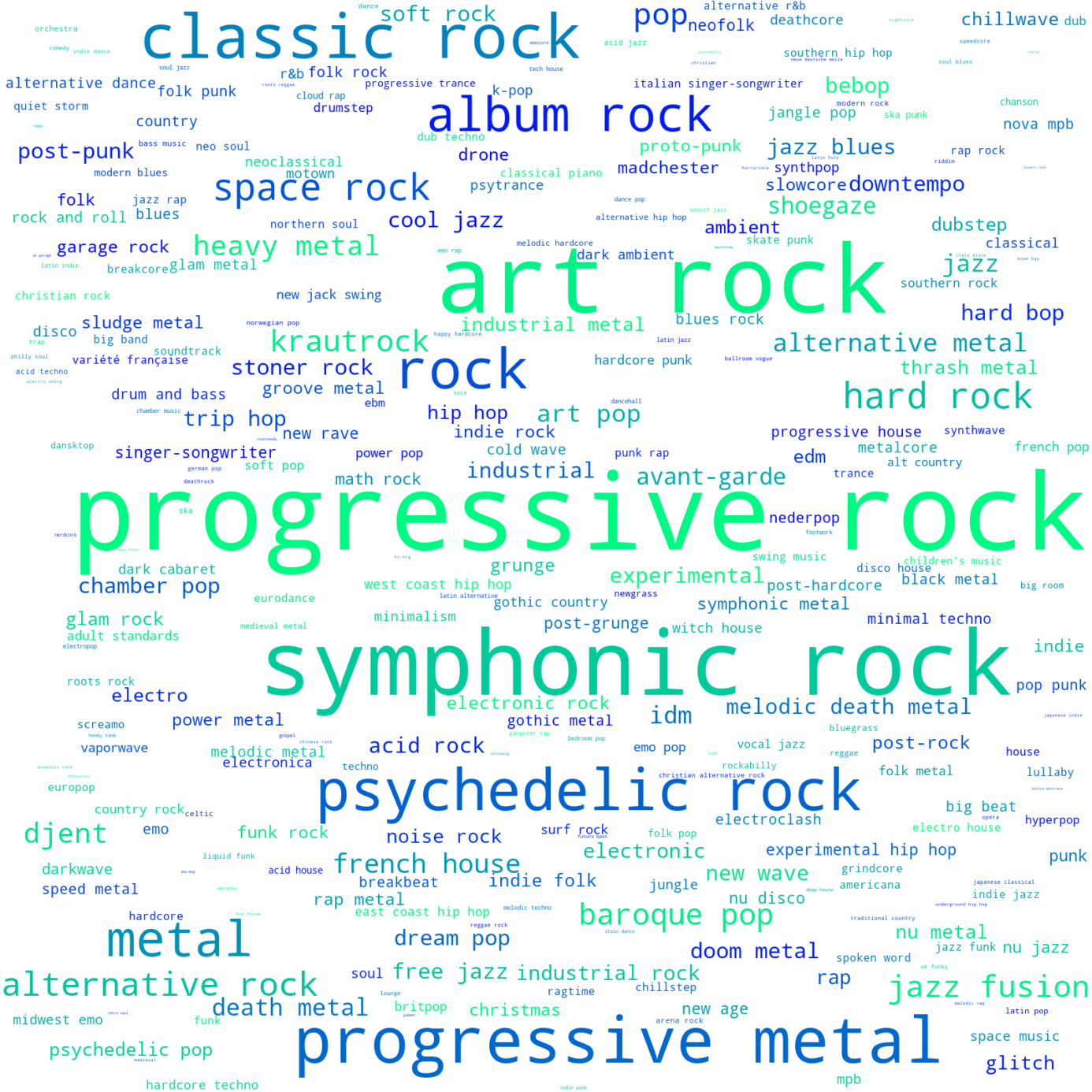
Preview
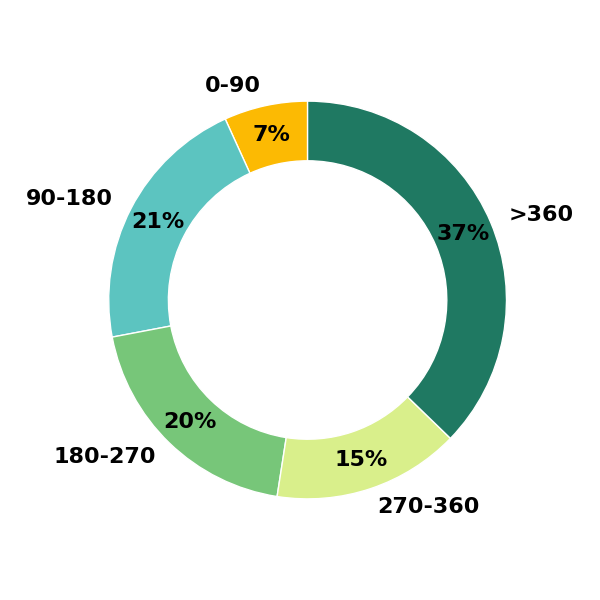
Popularity Distribution in Dataset
Preview
Count of Raw Text in Dataset
Preview
Caption
Preview
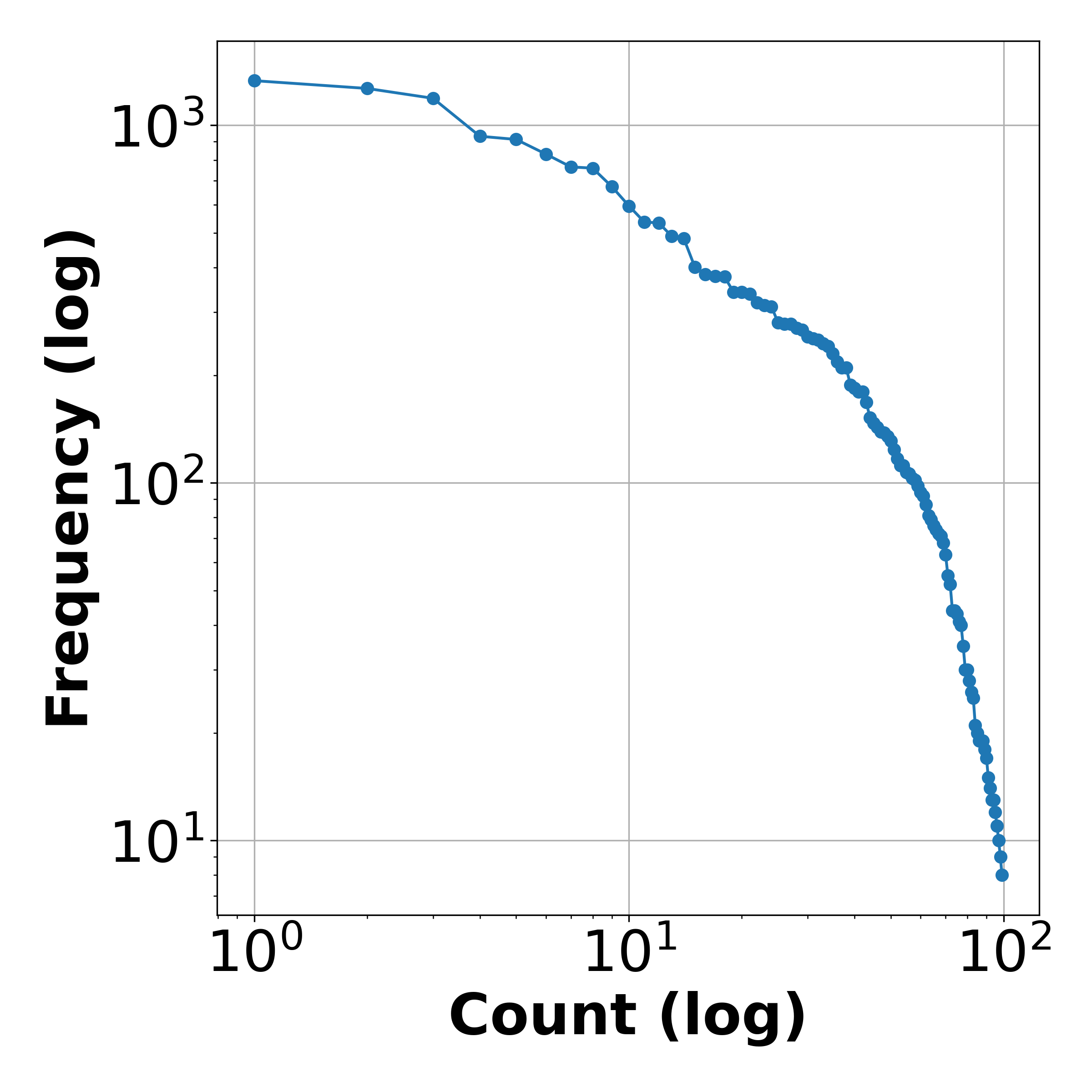
Genre Frequency in Dataset (log scale)
Preview
Enter Caption
Preview